
python 한글 이름 랜덤하게 생성 하기
프로젝트를 진행하면서 랜덤한 한글이름 데이터가 필요하여 찾아 만들어 보았다.
관련하여 비슷하게 고민을 갖을 것을 대비하여 정리 하여 보았다.
python 한글 이름 랜덤하게 생성 하기 위해서 3가지 방법을 실행 해 보았다.
개발 환경으로는 python 활용을 위해 jupyter notebook을 활용하였다.
1. 자음 모음 조합 생성
- 필요 라이브러리
pip install random
- 소스
import random # 한글 자음과 모음 리스트 consonants = ["ㄱ", "ㄴ", "ㄷ", "ㄹ", "ㅁ", "ㅂ", "ㅅ", "ㅇ", "ㅈ", "ㅊ", "ㅋ", "ㅌ", "ㅍ", "ㅎ"] vowels = ["ㅏ", "ㅑ", "ㅓ", "ㅕ", "ㅗ", "ㅛ", "ㅜ", "ㅠ", "ㅡ", "ㅣ"] def combine_jamo(consonant, vowel): # 유니코드 한글 음절 시작 위치 start = 0xAC00 # 자음, 모음 인덱스 consonant_index = consonants.index(consonant) vowel_index = vowels.index(vowel) # 초성, 중성, 종성 인덱스 조합 syllable_index = consonant_index * 21 * 28 + vowel_index * 28 return chr(start + syllable_index) def generate_korean_syllable(): consonant = random.choice(consonants) vowel = random.choice(vowels) return combine_jamo(consonant, vowel) def generate_korean_name(length=2): surname = generate_korean_syllable() first_name = ''.join(generate_korean_syllable() for _ in range(length)) return f"{surname}{first_name}" # 랜덤 한글 이름 생성 for _ in range(10): print(generate_korean_name()) - 실행화면

- 결과 : 원하는 이름들의 조합으로 나와 준수하지만 다양성이 낮게 나온다.
2. 샘플 이름의 조합을 통한 생성
-
- 필요 라이브러리
pip install random
- 소스
import random # 자주 사용되는 성씨와 이름 리스트 surnames = ["김", "이", "박", "최", "정", "강", "조", "윤", "장", "임"] first_names = [ "민준", "서준", "예준", "도윤", "시우", "하준", "주원", "지호", "지후", "준서", "서연", "서윤", "지우", "하은", "하윤", "민서", "지민", "수아", "지안", "지아" ] def generate_korean_name(): surname = random.choice(surnames) first_name = random.choice(first_names) return f"{surname} {first_name}" # 랜덤 한글 이름 생성 for _ in range(10): print(generate_korean_name()) - 실행 화면

-
- 결과 : 한글의 우수성을 보여 줄 수 있지만 외계어에 가까운 한글이 나온다.
3. 오픈 소스를 활용한 생성
- 필요라이브러리
pip install beautifulsoup4 korean-name-generator
- 소스
mport urllib import json from urllib import parse from urllib.request import Request, urlopen from random import randrange from bs4 import BeautifulSoup from korean_name_generator import namer #최종 생성 되는 사람을 저장하는 변수 users = [] # 남성 / 여성 10명씩 male_names = [] male_count = 10 female_names = [] female_count = 10 # 남성 10명 생성 while len(male_names) < male_count: name = namer.generate(True) if name not in male_names: male_names.append(name) # 여성 10명 생성 while len(female_names) < female_count: name = namer.generate(False) if name not in female_names: female_names.append(name) # 한글이름을 영어로 번역할 주소 naver_url = 'https://dict.naver.com/name-to-roman/translation/?query=' def get_eng_name(name): name_url = naver_url + urllib.parse.quote(name) req = Request(name_url) res = urlopen(req) html = res.read().decode('utf-8') bs = BeautifulSoup(html, 'html.parser') name_tags = bs.select('#container > div > table > tbody > tr > td > a') names = [name_tag.text for name_tag in name_tags] if len(names) == 0: return 'username' return names[0] # 남성 if male_count > 0: for i, male_name in enumerate(male_names): male = {} male['id'] = i + 1 male['name'] = male_name male['gender'] = 'M' male['age'] = 10 + 10 * int(i / (male_count/5)) + randrange(10) try: male['username'] = get_eng_name( male_name).lower().replace(' ', '.') + '{:04d}'.format(i + 1) except: male['username'] = 'username' + '{:04d}'.format(i + 1) male['email'] = male['username'] + '@example.com' users.append(male) if female_count > 0: for i, female_name in enumerate(female_names): female = {} female['id'] = i + male_count + 1 female['name'] = female_name female['gender'] = 'F' female['age'] = 10 + 10 * int(i / (female_count/5)) + randrange(10) try: female['username'] = get_eng_name( female_name).lower().replace(' ', '.') + '{:04d}'.format(i + male_count + 1) except: female['username'] = 'username' + '{:04d}'.format(i + 1) female['email'] = female['username'] + '@example.com' users.append(female) for item in users: print(f'{item}') - 실행결과
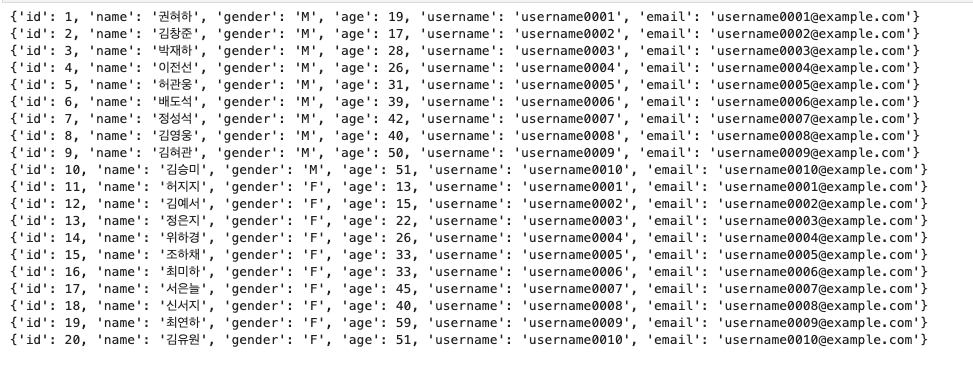
- 결론 : 오픈 소스 답게 가장 준수한 이름이 나열된다.
데이터 처리 및 AI 활용을 위하여 python언어가 여러가지 응용하는데 좋은 언어라 생각한다.
먼저 포스팅 한 위치정보를 통한 출퇴근 체크 와 같이 그때 그때 생각나는 아이디어를 구현하는데 타월한 언어인 것 같다.
간단하게 정리하는 글로 또 찾아 뵙고자 한다. Google Map을 활용하여 위치정보 추출하는 Python코드출퇴근 정보 추출 Google Map을 활용하여 위치정보 추출하는 Python코드를 만드려 한다. Google Map 타임 라인 정보는 안드로이드 또는 아이폰이나 상관 없이 자신의 위치 정보를 실시간으로 남길 수 있다. ... Read more
Google Map을 활용하여 위치정보 추출하는 Python코드출퇴근 정보 추출 Google Map을 활용하여 위치정보 추출하는 Python코드를 만드려 한다. Google Map 타임 라인 정보는 안드로이드 또는 아이폰이나 상관 없이 자신의 위치 정보를 실시간으로 남길 수 있다. ... Read more - 필요 라이브러리